State-Based Pushing Environment with Static Obstacles#
The StateBasedStaticObstaclePushingEnv is a simple pushing environment with two static obstacles.
The aim is to push the object with the mover to the desired goal position without collisions by specifying either the jerk or the
acceleration of the mover. A collision is detected, if the mover leaves the tiles (think of this as a collision with a wall) or if the
mover or the object collide with one of the obstacles.
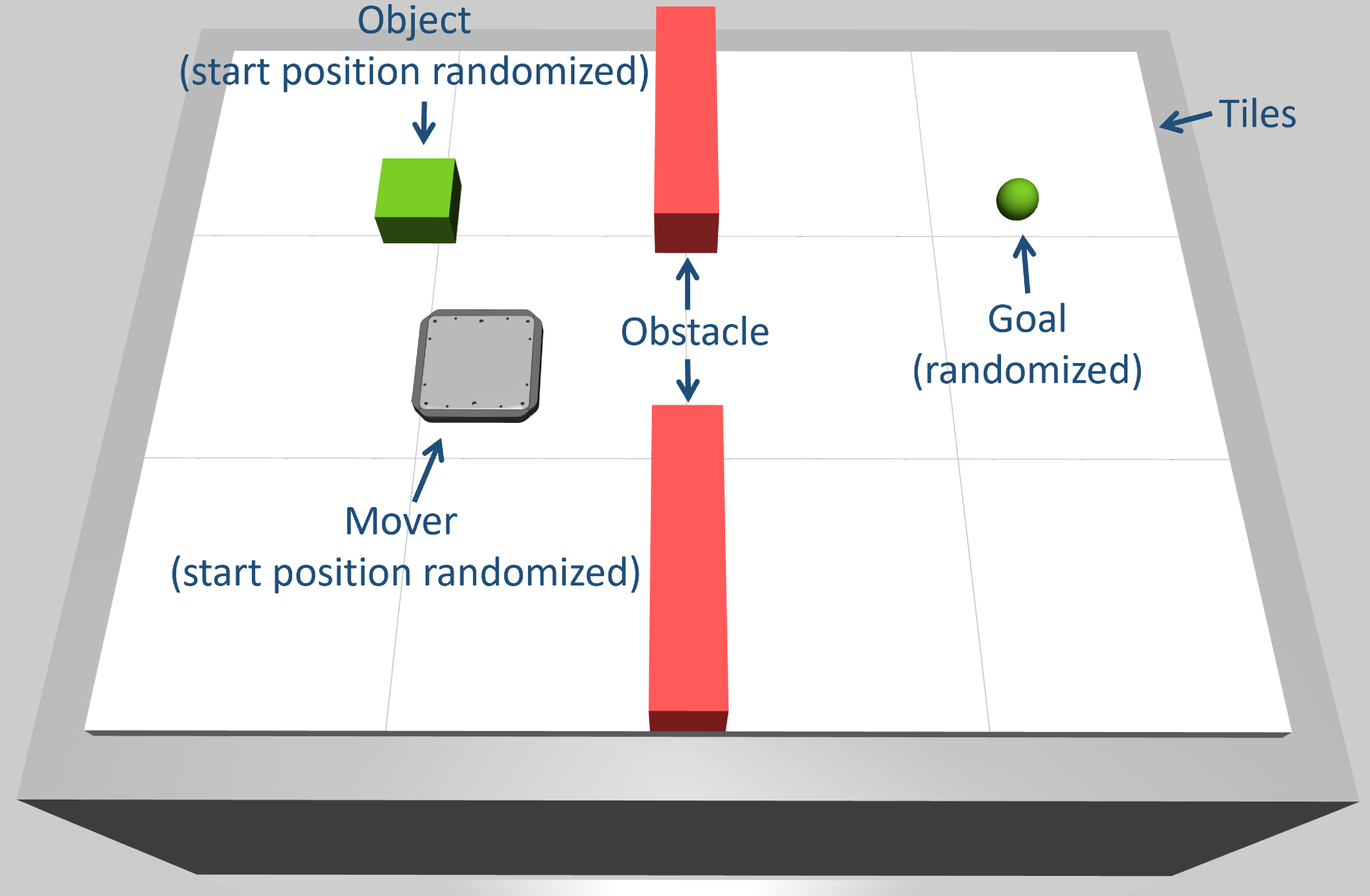
The difficulty of the task can be adjusted by changing the size of the obstacles, i.e. the larger the obstacles, the greater the difficulty.
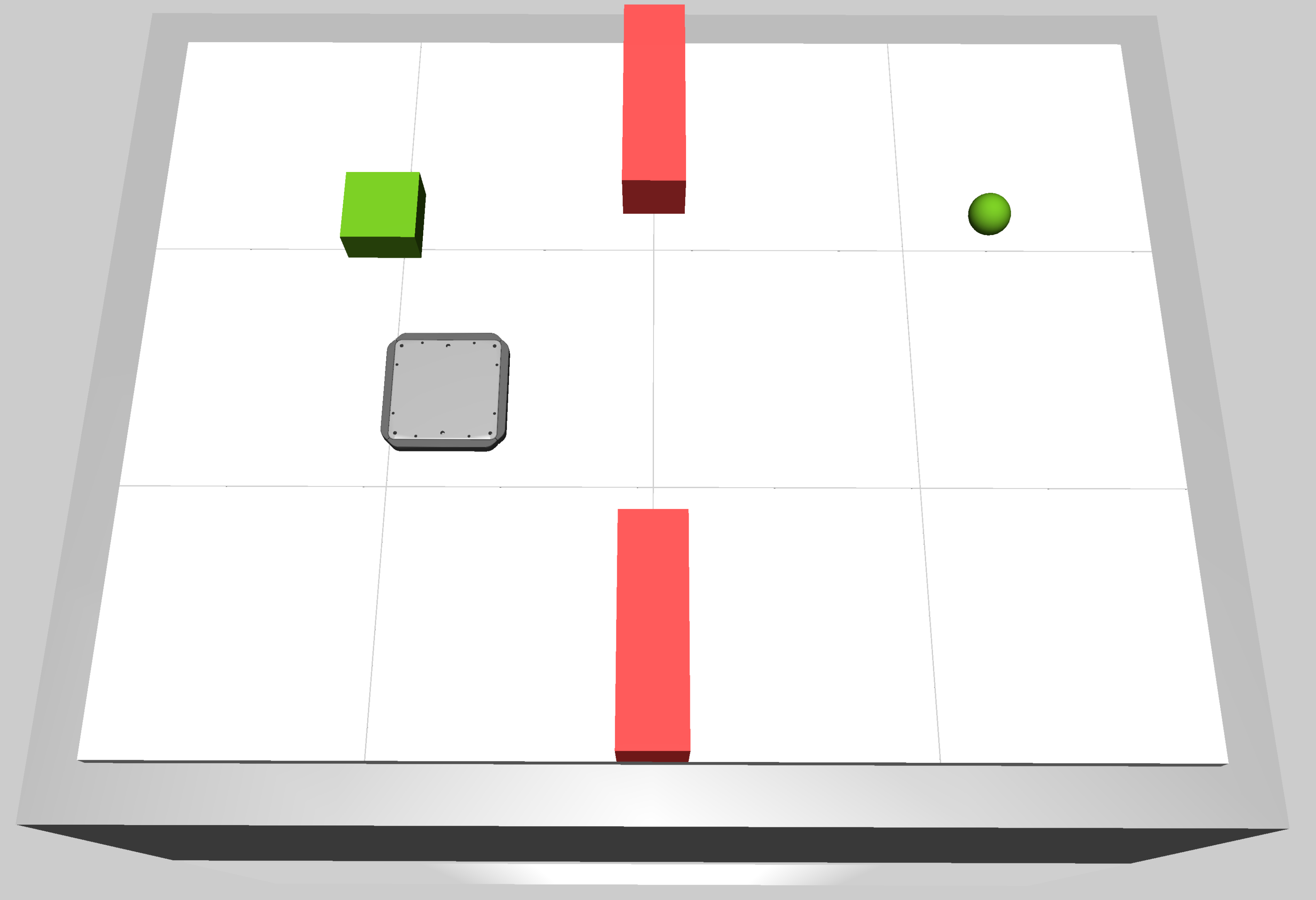
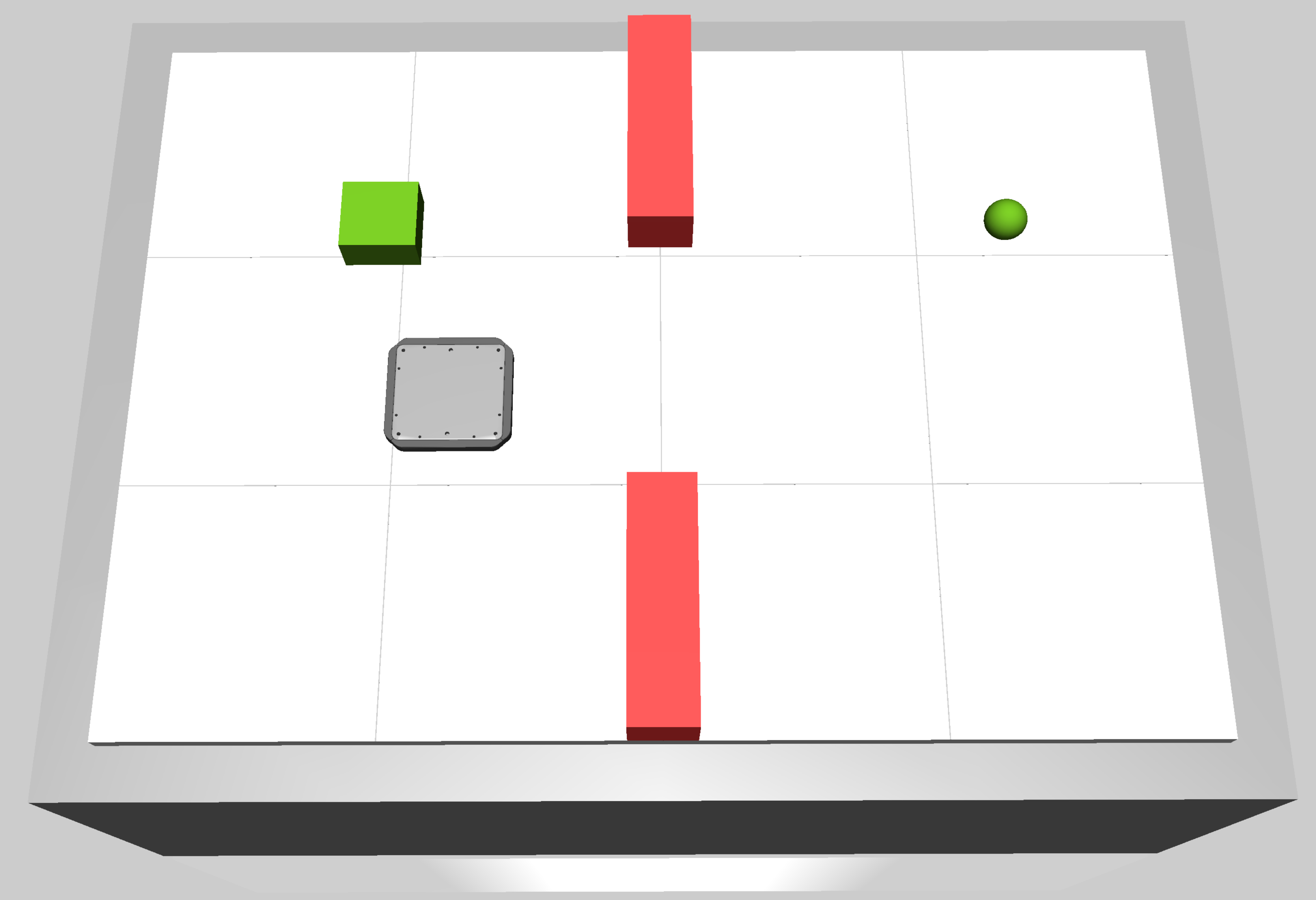
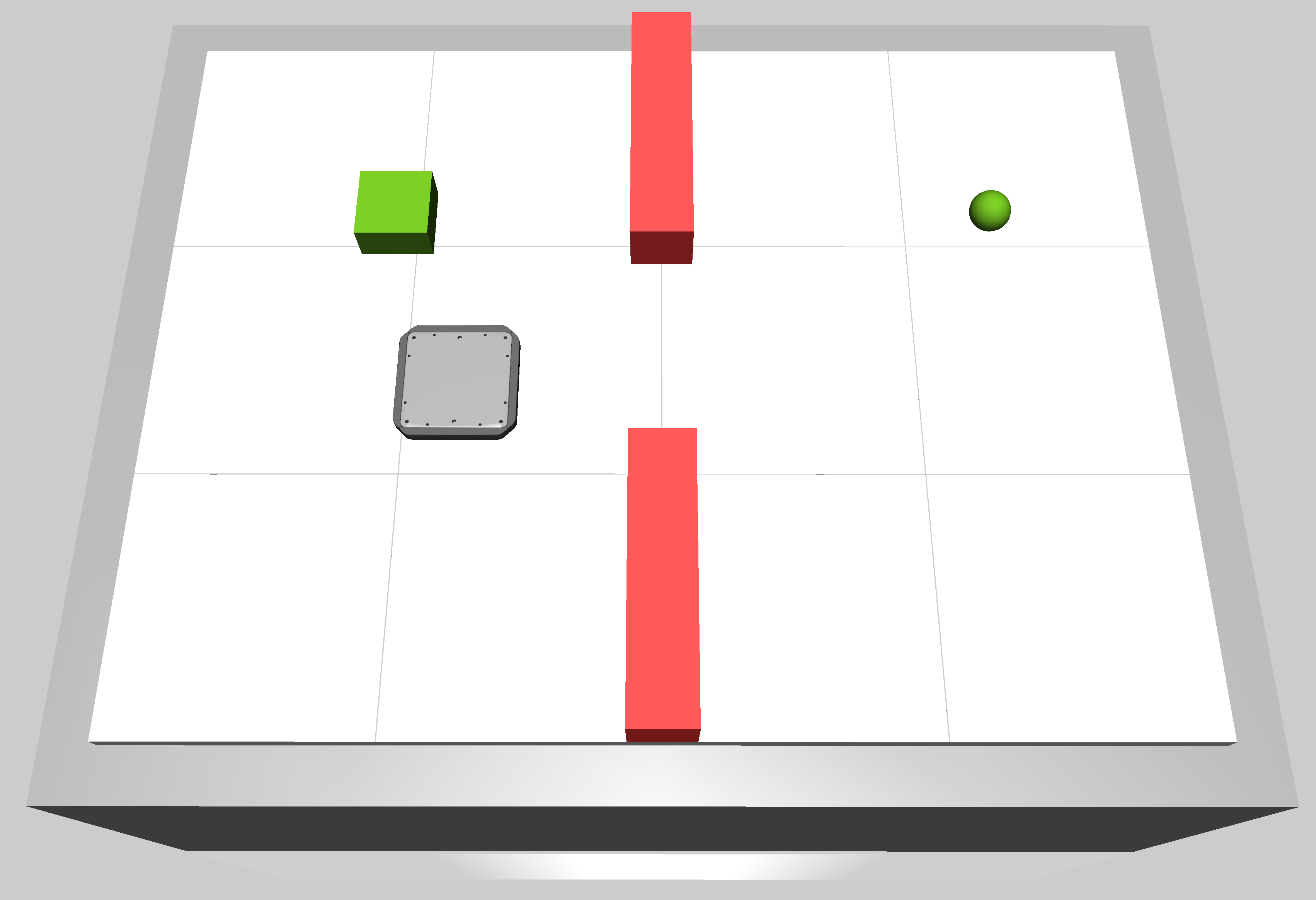
The size of the obstacles can be changed by setting the obstacle_mode. The following modes are available:
simple:
medium:
hard:
- random:
The size of the obstacles is chosen uniformly at random. The minimum obstacle size is the one used in the
obstacle_modesimple. The maximum obstacle size is the one used in theobstacle_modehard.
- curriculum:
Increases the size of the obstacle using a curriculum. The curriculum is kept simple. The initial
obstacle_modeissimple. After 800 episodes, theobstacle_modeis automatically set tomedium. After an additional 800 episodes, theobstacle_modeis changed tohardfor the remaining episodes.
The start positions of the mover and object as well as the object’s goal position are chosen randomly at the start of a new episode. This environment contains only one object and one mover. The tiles are arranged in a 4x3 layout. In this environment, positions, velocities, accelerations, and jerks have the units m, m/s, m/s² and m/s³, respectively.
Observation Space#
The observation space of this environment is a dictionary containing the following keys and values:
Key |
Value |
|---|---|
observation |
|
achieved_goal |
a numpy array of shape (2,) containing the current (x,y)-position of the object w.r.t. the base frame |
desired_goal |
a numpy array of shape (2,) containing the desired (x,y)-position of the object w.r.t. the base frame |
Action Space#
The action space is continuous and 2-dimensional. If learn_jerk=True, an action
represents the desired jerks in x and y direction of the base frame (unit: m/s³), where j_max is the maximum possible jerk (see
environment parameters).
Accordingly, if learn_jerk=False, an action
represents the accelerations in x and y direction of the base frame (unit: m/s²), where a_max is the maximum possible acceleration
(see environment parameters).
Immediate Rewards#
The agent receives a reward of 0 if the object has reached its goal without a collision. For each timestep in which the object has not reached its goal and in which there is no collision, the environment emits a small negative reward of -1. In the case of a collision, the agent receives a large negative reward of -50.
Episode Termination and Truncation#
Each episode has a time limit of 25 environment steps. If the time limit is reached, the episode is truncated. Thus, each episode has 25 environment steps, except that the mover collides with a wall. In this case, the episode terminates immediately regardless of the time limit. An episode is not terminated when the object reaches its goal position, as the object has to remain close to the desired goal position until the end of an episode.
Note
The term ‘episode steps’ refers to the number of calls of env.steps(). The number of MuJoCo simulation steps, i.e. control
cycles, is a multiple of the number of episode steps.
Environment Reset#
When the environment is reset, new (x,y) start positions for the mover and the object as well as a new goal position are chosen at random. It is ensured that the new start position of the mover is collision-free. In addition, the object’s start position is chosen such that the mover fits between the wall and the object. This is important to ensure that the object can be pushed in all directions.
Basic Usage#
The following example shows how to train an agent using Stable-Baselines3. To use the example, please install Stable-Baselines3 as described in the documentation.
Note
This is a simplified example that is not guaranteed to converge, as the default parameters are used. However, it is important to note that
the parameter copy_info_dict is set to True. This way, it is not necessary to check for collision again to compute the reward when a
transition is relabeled by HER, since the information is already available in the info-dict.
import numpy as np
import gymnasium as gym
from stable_baselines3 import SAC, HerReplayBuffer
import magbotsim
gym.register_envs(magbotsim)
render_mode = None
mover_params = {'size': np.array([0.113 / 2, 0.113 / 2, 0.012 / 2]), 'mass': 0.628}
collision_params = {'shape': 'box', 'size': np.array([0.113 / 2 + 1e-6, 0.113 / 2 + 1e-6]), 'offset': 0.0, 'offset_wall': 0.0}
env_params = {'mover_params': mover_params, 'collision_params': collision_params, 'render_mode': render_mode}
env = gym.make('StateBasedStaticObstaclePushingEnv-v0', **env_params)
# copy_info_dict=True, as information about collisions is stored in the info dictionary to avoid
# computationally expensive collision checking calculations when the data is relabeled (HER)
model = SAC(
policy='MultiInputPolicy',
env=env,
replay_buffer_class=HerReplayBuffer,
replay_buffer_kwargs={'copy_info_dict': True},
verbose=1
)
model.learn(total_timesteps=int(1e6))
Version History#
v0: initial version of the environment
Parameters#
- class magbotsim.rl_envs.object_manipulation.pushing.state_based_static_obstacle_env.StateBasedStaticObstaclePushingEnv(obstacle_mode: str = 'simple', mover_params: dict[str, Any] | None = None, initial_mover_zpos: float = 0.002, std_noise: ndarray | float = 1e-05, render_mode: str | None = 'human', render_every_cycle: bool = False, num_cycles: int = 40, collision_params: dict[str, Any] | None = None, v_max_xy: float = 2.0, a_max_xy: float = 10.0, j_max_xy: float = 100.0, learn_jerk: bool = False, threshold_pos: float = 0.05, use_mj_passive_viewer: bool = False)[source]
Bases:
BasicMagBotSingleAgentEnvA simple object pushing environment with two static obstacles.
- Parameters:
obstacle_mode – the obstacle mode of this environment which determines the size of the obstacles and the difficulty of the task, defaults to ‘simple’. Can be ‘hard’ (large obstacles), ‘medium’ (medium-sized obstacles), ‘simple’ (small obstacles), ‘random’ (choose size of the obstacles at random), or ‘curriculum’ (increase the size of the obstacle using a curriculum).
mover_params –
Dictionary specifying mover properties. If None, default values are used. Supported keys:
- mass (float | numpy.ndarray): Mass in kilograms. Options:
Single float: Same mass for all movers
1D array (num_movers,): Individual masses per mover
Default: 1.24 [kg]
- shape (str | list[str]): Mover shape type. Must be one of:
’box’: Rectangular cuboid
’cylinder’: Cylindrical shape
’mesh’: Custom 3D mesh
Default: ‘box’
- size (numpy.ndarray): Shape dimensions in meters. Format depends on shape:
For ‘box’: Half-sizes (x, y, z)
For ‘cylinder’: (radius, height, _)
For ‘mesh’: Computed from mesh dimensions multiplied by scale factors in mesh[‘scale’]
Specification options: - 1D array (3,): Same size for all movers - 2D array (num_movers, 3): Individual sizes per mover
Default: [0.155/2, 0.155/2, 0.012/2] [m]
- mesh (dict): Configuration for mesh-based shapes. Required when shape=’mesh’. Contains:
- mover_stl_path (str): Path to mover mesh STL file or one of the predefined meshes:
’beckhoff_apm4330_mover’: Beckhoff APM4220 mover mesh (default)
’beckhoff_apm4220_mover’: Beckhoff APM4220 mover mesh
’beckhoff_apm4550_mover’: Beckhoff APM4550 mover mesh
’planar_motor_M3-06’: Planar Motor M3-06 mover mesh
’planar_motor_M3-15’: Planar Motor M3-15 mover mesh
’planar_motor_M3-25’: Planar Motor M3-25 mover mesh
’planar_motor_M4-11’: Planar Motor M4-11 mover mesh
’planar_motor_M4-18’: Planar Motor M4-18 mover mesh
- bumper_stl_path (str | None): Path to bumper mesh STL file or one of the predefined meshes:
’beckhoff_apm4330_bumper’: Beckhoff APM4330 bumper mesh (default)
’beckhoff_apm4220_bumper’: Beckhoff APM4220 bumper mesh
’beckhoff_apm4550_bumper’: Beckhoff APM4550 bumper mesh
- bumper_mass (float | numpy.ndarray): Bumper mass in kilograms. Can be specified as:
Single float: Same mass applied to all bumpers
1D array (num_movers,): Individual masses for each bumper
Default: 0.1 [kg]
- scale (numpy.ndarray): Scale factors for mesh dimensions (x, y, z). Multiplied with the
mesh geometry. Specification options: - 1D array (3,): Same scale factors applied to all movers - 2D array (num_movers, 3): Individual scale factors for each mover
Default: [1.0, 1.0, 1.0] (no scaling)
- material (str | list[str]): Material name to apply to the mover. Can be specified as:
Single string: Same material for all movers
List of strings: Individual materials for each mover
Default: “gray” for movers without goals, color-coded materials for movers with goals
Note: Custom mesh STL files must have their origin at the mover’s center.
initial_mover_zpos – the initial distance between the bottom of the mover and the top of a tile, defaults to 0.002 [m]
std_noise – the standard deviation of a Gaussian with zero mean used to add noise, defaults to 1e-5. The standard deviation can be used to add noise to the mover’s position, velocity and acceleration. If you want to use different standard deviations for position, velocity and acceleration use a numpy array of shape (3,); otherwise use a single float value, meaning the same standard deviation is used for all three values.
render_mode – the mode that is used to render the frames (‘human’, ‘rgb_array’ or None), defaults to ‘human’. If set to None, no viewer is initialized and used, i.e. no rendering. This can be useful to speed up training.
render_every_cycle – whether to call
render()after each integrator step in thestep()method, defaults to False. Rendering every cycle leads to a smoother visualization of the scene, but can also be computationally expensive. Thus, this parameter provides the possibility to speed up training and evaluation. Regardless of this parameter, the scene is always rendered afternum_cycleshave been executed ifrender_mode != None.num_cycles – the number of control cycles for which to apply the same action, defaults to 40
collision_params – _description_, defaults to None
v_max_xy – the maximum velocity in x- and y-direction, defaults to 2.0 [m/s]
a_max_xy – the maximum acceleration in x- and y-direction, defaults to 10.0 [m/s²]
j_max_xy – the maximum jerk in x- and y-direction (only used if
learn_jerk=True), defaults to 100.0 [m/s³]learn_jerk – whether to learn the jerk, defaults to False. If set to False, the acceleration is learned, i.e. the policy output.
threshold_pos – the position threshold used to determine whether a mover has reached its goal position, defaults to 0.05 [m]
use_mj_passive_viewer – whether the MuJoCo passive_viewer should be used, defaults to False. If set to False, the Gymnasium MuJoCo WindowViewer with custom overlays is used.
- _after_mujoco_step_callback()[source]
Check whether corrective movements (overshoot or distance corrections) occurred and increase the corresponding counter if necessary.
- _before_mujoco_step_callback(action: ndarray) None[source]
Apply the next action, i.e. it sets the jerk or acceleration, ensuring the minimum and maximum velocity and acceleration (for one cycle).
- Parameters:
action – a numpy array of shape (num_movers * 2,), which specifies the next action (jerk or acceleration)
- _check_for_other_collisions_callback()[source]
Check whether the object or mover collide with an obstacle.
- Returns:
whether there is a collision (mover-obstacle or object-obstacle, bool)
a dictionary with keys
obstacle_object_collisionandobstacle_mover_collisionthat contains bool values indicating what type of collision occurred (mover-obstacle or object-obstacle)
- _custom_xml_string_callback(custom_model_xml_strings: dict | None) dict[str, str][source]
For each mover, this callback adds actuators to the
custom_model_xml_strings-dict, depending on whether the jerk or acceleration is the output of the policy.- Parameters:
custom_model_xml_strings – the current
custom_model_xml_strings-dict which is modified by this callback- Returns:
the modified
custom_model_xml_strings-dict
- _reset_callback(options: dict[str, Any] | None = None) None[source]
Reset the start position of mover and object and the object goal position and reload the model. It is ensured that the new start position of the mover is collision-free, i.e. no wall collision and no collision with the object. In addition, the object’s start position is chosen such that the mover fits between the wall and the object. This is important to ensure that the object can be pushed in all directions.
It is also possible to explicitly specify start positions for mover and object, as well as the object’s goal position by using the keys ‘mover_xy_start_pos’, ‘object_xy_start_pos’, and ‘object_xy_goal_pos’ in the
options-dict (each numpy arrays of shape (2,)). The start position of mover and object are sampled uniformly at random if the corresponding key is not in theoptions-dict. Note that there is no check whether mover or object collide with an obstacle due to computational efficiency. Since min and max x,y start positions of object and mover are chosen such that a collision with the obstacle cannot occur if the start positions are randomly sampled. In addition, if the object’s start position is specified by the user, the distance to the mover is not checked.- Parameters:
options – can be used to specify start positions for mover and object and a goal position for the object (keys: ‘mover_xy_start_pos’, ‘object_xy_start_pos’, ‘object_xy_goal_pos’)
- _step_callback(action)[source]
Ensures the maximum dynamics of the actions (accelerations or jerks).
- Parameters:
action – a numpy array of shape (num_movers * 2,), which specifies the next action (jerk or acceleration)
- Returns:
the possibly modified action (shape: (num_movers,2))
- close() None[source]
Close the environment.
- compute_reward(achieved_goal: ndarray, desired_goal: ndarray, info: dict[str, Any] | None = None) ndarray | float[source]
Compute the immediate reward.
- Parameters:
achieved_goal – a numpy array of shape (batch_size, length achieved_goal) or (length achieved_goal,) containing the already achieved (x,y)-positions of an object
desired_goal – a numpy array of shape (batch_size, length desired_goal) or (length desired_goal,) containing the (x,y) goal positions of an object
info – a dictionary containing auxiliary information, defaults to None
- Returns:
a single float value or a numpy array of shape (batch_size,) containing the immediate rewards
- compute_terminated(achieved_goal: ndarray, desired_goal: ndarray, info: dict[str, Any] | None = None) ndarray | bool[source]
Check whether a terminal state is reached. A state is terminal when the mover or object collides with a wall or the obstacle.
- Parameters:
achieved_goal – a numpy array of shape (batch_size, length achieved_goal) or (length achieved_goal,) containing the already achieved (x,y)-positions of an object
desired_goal – a numpy array of shape (batch_size, length desired_goal) or (length desired_goal,) containing the (x,y) goal positions of an object
info – a dictionary containing auxiliary information, defaults to None
- Returns:
- if batch_size > 1:
a numpy array of shape (batch_size,). An entry is True if the state is terminal, False otherwise
- if batch_size = 1:
True if the state is terminal, False otherwise
- compute_truncated(achieved_goal: ndarray, desired_goal: ndarray, info: dict[str, Any] | None = None) ndarray | bool[source]
Check whether the truncation condition is satisfied. The truncation condition (a time limit in this environment) is automatically checked by the Gymnasium TimeLimit Wrapper, which is why this method always returns False.
- Parameters:
achieved_goal – a numpy array of shape (batch_size, length achieved_goal) or (length achieved_goal,) containing the already achieved (x,y)-positions of an object
desired_goal – a numpy array of shape (batch_size, length desired_goal) or (length desired_goal,) containing the (x,y) goal positions of an object
info – a dictionary containing auxiliary information, defaults to None
- Returns:
- if batch_size > 1:
a numpy array of shape (batch_size,) in which all entries are False
- if batch_size = 1:
False
- ensure_max_dyn_val(current_values: ndarray, max_value: float, next_derivs: ndarray) tuple[ndarray, ndarray][source]
Ensure the minimum and maximum dynamic values per cycle.
- Parameters:
current_values – the current velocity or acceleration specified as a numpy array of shape (2,) or (num_checks,2)
max_value – the maximum velocity or acceleration (float)
next_derivs – the next derivative (acceleration or jerk) used for one integrator step specified as a numpy array of shape (2,) or (num_checks,2)
- Returns:
the next velocity or acceleration and the next derivative (acceleration or jerk) corresponding to the next action that must be applied to ensure the minimum and maximum dynamics (each of shape (num_checks,2))
- get_current_num_distance_corrections() int[source]
Return the current number of distance corrections measured within the current episode.
- Returns:
the current number of distance corrections measured within the current episode
- get_current_num_overshoot_corrections() int[source]
Return the current number of overshoot corrections measured within the current episode.
- Returns:
the current number of overshoot corrections measured within the current episode
- reload_model(mover_start_xy_pos: ndarray | None = None) None[source]
Generate a new model XML string with new start positions for mover and object and a new object goal position and reload the model. In this environment, it is necessary to reload the model to ensure that the actuators work as expected.
- Parameters:
mover_start_xy_pos – None or a numpy array of shape (num_movers,2) containing the (x,y) starting positions of each mover, defaults to None. If set to None, the movers will be placed in the center of the tiles that are added to the XML string first.
- update_cached_actuator_mujoco_data() None[source]
Update all cached information about MuJoCo actuators, such as names and ids.