State-Based Push-Box Environment#
The StateBasedPushBoxEnv is an object pushing environment with a T-shaped object:
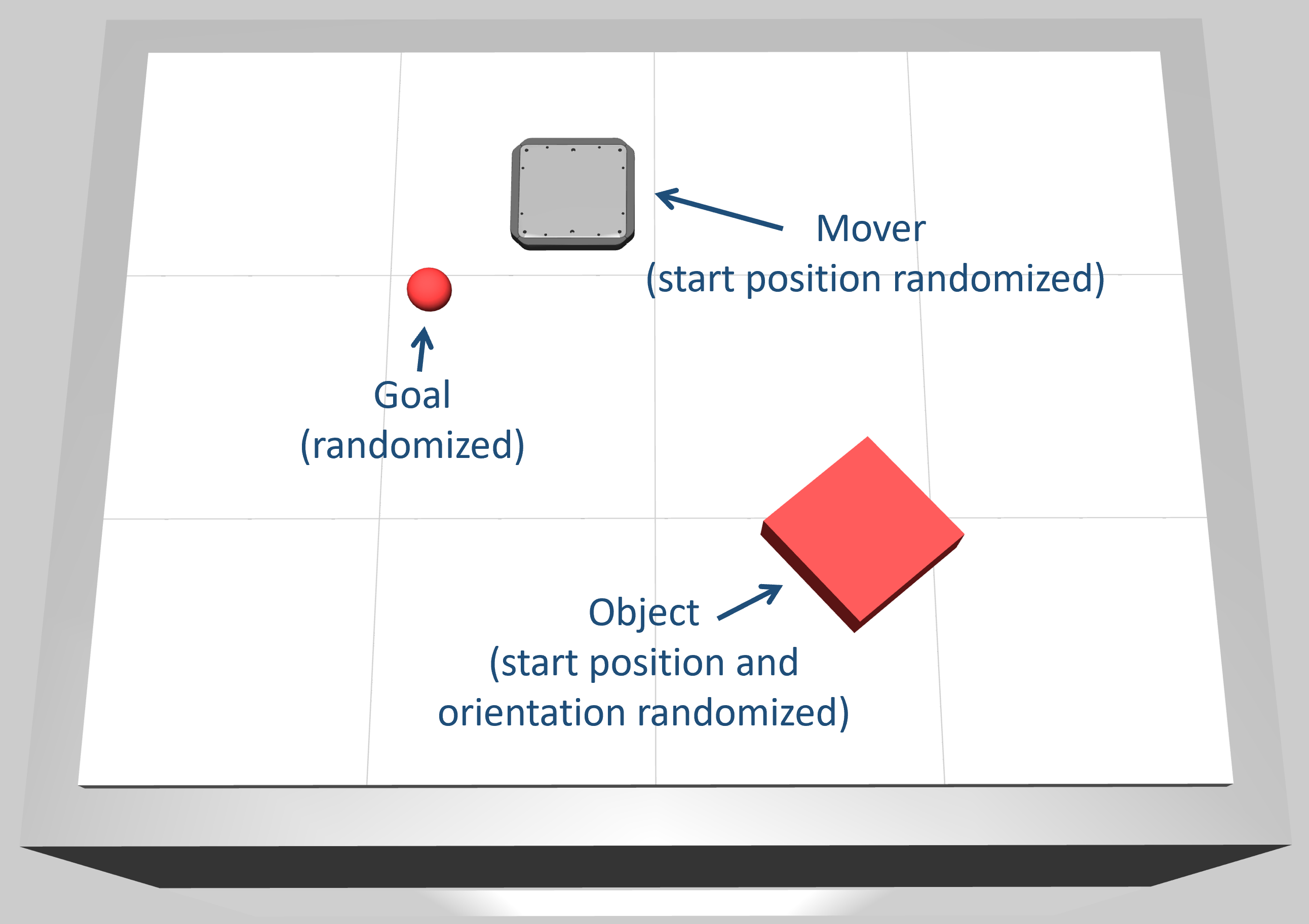
This environment is a preconfigured version of State-Based Global Pushing Environment specifically designed for the box pushing task,
similar to the FetchPush-Environment contained in the Gymnasium-Robotics library
and introduced in Multi-Goal Reinforcement Learning: Challenging Robotics Environments and Request for Research.
However, in this environment, the number of movers used for pushing can be configured, making it possible to control multiple movers.
Please refer to the State-Based Global Pushing Environment for additional information about the observation space, action space, immediate rewards,
episode termination/truncation, and environment reset.
Basic Usage#
The following example shows how to train an agent using Stable-Baselines3. To use the example, please install Stable-Baselines3 as described in the documentation.
Note
This is a simplified example that is not guaranteed to converge, as the default parameters are used. However, it is important to note that
the parameter copy_info_dict is set to True. This way, it is not necessary to check for collision again to compute the reward when a
transition is relabeled by HER, since the information is already available in the info-dict.
import numpy as np
import gymnasium as gym
from stable_baselines3 import SAC, HerReplayBuffer
import magbotsim
gym.register_envs(magbotsim)
render_mode = None
mover_params = {'size': np.array([0.113 / 2, 0.113 / 2, 0.012 / 2]), 'mass': 0.628}
collision_params = {'shape': 'box', 'size': np.array([0.113 / 2 + 1e-6, 0.113 / 2 + 1e-6]), 'offset': 0.0, 'offset_wall': 0.0}
env_params = {'mover_params': mover_params, 'collision_params': collision_params, 'render_mode': render_mode}
env = gym.make('StateBasedPushBoxEnv-v0', **env_params)
# copy_info_dict=True, as information about collisions is stored in the info dictionary to avoid
# computationally expensive collision checking calculations when the data is relabeled (HER)
model = SAC(
policy='MultiInputPolicy',
env=env,
replay_buffer_class=HerReplayBuffer,
replay_buffer_kwargs={'copy_info_dict': True},
verbose=1
)
model.learn(total_timesteps=int(1e6))
Version History#
v0: initial version of the environment
Parameters#
- class magbotsim.rl_envs.object_manipulation.pushing.state_based_push_box_env.StateBasedPushBoxEnv(num_movers: int = 1, mover_params: dict[str, Any] | None = None, layout_tiles: ndarray | None = None, initial_mover_zpos: float = 0.003, std_noise: ndarray | float = 1e-05, render_mode: str | None = 'human', render_every_cycle: bool = False, num_cycles: int = 40, collision_params: dict[str, Any] | None = None, object_ranges: MutableMapping[str, tuple[float, float]] = {'depth': (0.02, 0.02), 'height': (0.06, 0.06), 'mass': (0.3, 0.3), 'radius': (0.05, 0.05), 'segment_width': (0.02, 0.02), 'width': (0.06, 0.06)}, v_max_xy: float = 2.0, a_max_xy: float = 10.0, j_max_xy: float = 100.0, learn_mover_c_rotation: bool = False, p_max_c: float | None = None, v_max_c: float = 122.17305, a_max_c: float = 122.17305, j_max_c: float = 610.86524, object_sliding_friction: float = 0.6, object_torsional_friction: float = 0.0001, learn_jerk: bool = False, early_termination_steps: int | None = None, max_position_err: float = 0.05, collision_penalty: float = -10, per_step_penalty: float = -0.01, object_at_goal_reward: float = 1.0, use_mj_passive_viewer: bool = False)[source]
Bases:
StateBasedGlobalPushingEnvA simplified object pushing environment with a box to be pushed.
- Parameters:
num_movers – the number of movers in the environment, defaults to 1
mover_params –
a dictionary that can be used to specify the mass and size of each mover using the keys ‘mass’ or ‘size’, defaults to None. To use the same mass and size for each mover, the mass can be specified as a single float value and the size as a numpy array of shape (3,). However, the movers can also be of different types, i.e. different masses and sizes. In this case, the mass and size should be specified as numpy arrays of shapes (num_movers,) and (num_movers,3), respectively. If set to None or only one key is specified, both mass and size or the missing value are set to the following default values:
mass: 1.24 [kg]
size: [0.155/2, 0.155/2, 0.012/2] (x,y,z) [m] (note: half-size)
layout_tiles – a numpy array of shape (height, width) that specifies the layout of the tiles, defaults to None. If None, a 4x3 grid of tiles is used.
initial_mover_zpos – the initial distance between the bottom of the mover and the top of a tile, defaults to 0.003
std_noise – the standard deviation of a Gaussian with zero mean used to add noise, defaults to 0.00001. The standard deviation can be used to add noise to the mover’s position, velocity and acceleration. If you want to use different standard deviations for position, velocity and acceleration use a numpy array of shape (3,); otherwise use a single float value, meaning the same standard deviation is used for all three values.
render_mode – the mode that is used to render the frames (‘human’, ‘rgb_array’ or None), defaults to ‘human’. If set to None, no viewer is initialized and used, i.e. no rendering. This can be useful to speed up training.
render_every_cycle – whether to call ‘render’ after each integrator step in the
step()method, defaults to False. Rendering every cycle leads to a smoother visualization of the scene, but can also be computationally expensive. Thus, this parameter provides the possibility to speed up training and evaluation. Regardless of this parameter, the scene is always rendered after ‘num_cycles’ have been executed ifrender_mode != None.num_cycles – the number of control cycles for which to apply the same action, defaults to 40
collision_params –
a dictionary that can be used to specify the following collision parameters, defaults to None:
collision shape (key: ‘shape’): can be ‘box’ or ‘circle’, defaults to ‘circle’
- size of the collision shape (key: ‘size’), defaults to 0.11 [m]:
- collision shape ‘circle’:
a single float value which corresponds to the radius of the circle, or a numpy array of shape (num_movers,) to specify individual values for each mover
- collision shape ‘box’:
a numpy array of shape (2,) to specify x and y half-size of the box, or a numpy array of shape (num_movers, 2) to specify individual sizes for each mover
- additional size offset (key: ‘offset’), defaults to 0.0 [m]: an additional safety offset that is added to the size of the
collision shape. Think of this offset as increasing the size of a mover by a safety margin.
- additional wall offset (key: ‘offset_wall’), defaults to 0.0 [m]: an additional safety offset that is added to the size
of the collision shape to detect wall collisions. Think of this offset as moving the wall, i.e. the edge of a tile without an adjacent tile, closer to the center of the tile.
object_ranges – a dictionary that specifies the range of object parameters for random sampling, defaults to DEFAULT_OBJECT_RANGES. Keys can include ‘width’, ‘height’, ‘depth’, ‘segment_width’, ‘radius’, ‘mass’. Each value is a tuple (min_value, max_value)
v_max_xy – the maximum velocity in x- and y-direction, defaults to 2.0 [m/s]
a_max_xy – the maximum acceleration in x- and y-direction, defaults to 10.0 [m/s²]
j_max_xy – the maximum jerk in x- and y-direction (only used if ‘learn_jerk=True’), defaults to 100.0 [m/s³]
learn_mover_c_rotation – whether to learn the mover’s c rotation, defaults to False. If False, the mover can only move in x- and y-direction.
p_max_c – the maximum c-orientation of the mover in rad, defaults to None. The specified limit must satisfy \(0<p_{max_c}\leq\pi\), but the position limit is symmetric. If None, the mover rotates without position limits.
v_max_c – the maximum velocity in c, defaults to 122.17305 [rad/s]
a_max_c – the maximum acceleration in c, defaults to 122.17305 [rad/s²]
j_max_c – the maximum jerk in c (only used if
learn_jerk=True), defaults to 610.86524 [rad/s³]object_sliding_friction – the sliding friction coefficient of the object, defaults to 0.6
object_torsional_friction – the torsional friction coefficient of the object, defaults to 0.0001
learn_jerk – whether to learn the jerk, defaults to False. If set to False, the acceleration is learned, i.e. the policy output.
early_termination_steps – the number of consecutive steps at goal after which the episode terminates early, defaults to None (no early termination)
max_position_err – the position threshold used to determine whether the object has reached its goal position, defaults to 0.05 [m]
collision_penalty – the reward penalty applied when a collision occurs, defaults to -10.0
per_step_penalty – the small negative reward applied at each time step to encourage efficiency, defaults to -0.01
object_at_goal_reward – the positive reward given when the object reaches the goal without collisions, defaults to 1.0
use_mj_passive_viewer – whether the MuJoCo passive_viewer should be used, defaults to False. If set to False, the Gymnasium MuJoCo WindowViewer with custom overlays is used.
- class magbotsim.rl_envs.object_manipulation.pushing.state_based_push_box_env.StateBasedPushBoxEnvB0(mover_params: dict[str, Any] | None = None, initial_mover_zpos: float = 0.003, std_noise: ndarray | float = 1e-05, render_mode: str | None = 'human', render_every_cycle: bool = False, num_cycles: int = 40, collision_params: dict[str, Any] | None = None, object_ranges: MutableMapping[str, tuple[float, float]] = {'depth': (0.02, 0.02), 'height': (0.06, 0.06), 'mass': (0.3, 0.3), 'radius': (0.05, 0.05), 'segment_width': (0.02, 0.02), 'width': (0.06, 0.06)}, v_max_xy: float = 2, a_max_xy: float = 10, j_max_xy: float = 100, learn_mover_c_rotation: bool = False, p_max_c: float | None = None, v_max_c: float = 122.17305, a_max_c: float = 122.17305, j_max_c: float = 610.86524, object_sliding_friction: float = 0.6, object_torsional_friction: float = 0.0001, learn_jerk: bool = False, early_termination_steps: int | None = None, max_position_err: float = 0.05, collision_penalty: float = -10, per_step_penalty: float = -0.01, object_at_goal_reward: float = 1, use_mj_passive_viewer: bool = False)[source]
Bases:
StateBasedPushBoxEnvBenchmark 0 for the
StateBasedPushBoxEnvtask.
- class magbotsim.rl_envs.object_manipulation.pushing.state_based_push_box_env.StateBasedPushBoxEnvB1(mover_params: dict[str, Any] | None = None, initial_mover_zpos: float = 0.003, std_noise: ndarray | float = 1e-05, render_mode: str | None = 'human', render_every_cycle: bool = False, num_cycles: int = 40, collision_params: dict[str, Any] | None = None, object_ranges: MutableMapping[str, tuple[float, float]] = {'depth': (0.02, 0.02), 'height': (0.06, 0.06), 'mass': (0.3, 0.3), 'radius': (0.05, 0.05), 'segment_width': (0.02, 0.02), 'width': (0.06, 0.06)}, v_max_xy: float = 2, a_max_xy: float = 10, j_max_xy: float = 100, learn_mover_c_rotation: bool = False, p_max_c: float | None = None, v_max_c: float = 122.17305, a_max_c: float = 122.17305, j_max_c: float = 610.86524, object_sliding_friction: float = 0.6, object_torsional_friction: float = 0.0001, learn_jerk: bool = False, early_termination_steps: int | None = None, max_position_err: float = 0.05, collision_penalty: float = -10, per_step_penalty: float = -0.01, object_at_goal_reward: float = 1, use_mj_passive_viewer: bool = False)[source]
Bases:
StateBasedPushBoxEnvBenchmark 1 for the
StateBasedPushBoxEnvtask.
- class magbotsim.rl_envs.object_manipulation.pushing.state_based_push_box_env.StateBasedPushBoxEnvB2(mover_params: dict[str, Any] | None = None, initial_mover_zpos: float = 0.003, std_noise: ndarray | float = 1e-05, render_mode: str | None = 'human', render_every_cycle: bool = False, num_cycles: int = 40, collision_params: dict[str, Any] | None = None, object_ranges: MutableMapping[str, tuple[float, float]] = {'depth': (0.02, 0.02), 'height': (0.06, 0.06), 'mass': (0.3, 0.3), 'radius': (0.05, 0.05), 'segment_width': (0.02, 0.02), 'width': (0.06, 0.06)}, v_max_xy: float = 2, a_max_xy: float = 10, j_max_xy: float = 100, learn_mover_c_rotation: bool = False, p_max_c: float | None = None, v_max_c: float = 122.17305, a_max_c: float = 122.17305, j_max_c: float = 610.86524, object_sliding_friction: float = 0.6, object_torsional_friction: float = 0.0001, learn_jerk: bool = False, early_termination_steps: int | None = None, max_position_err: float = 0.05, collision_penalty: float = -10, per_step_penalty: float = -0.01, object_at_goal_reward: float = 1, use_mj_passive_viewer: bool = False)[source]
Bases:
StateBasedPushBoxEnvBenchmark 2 for the
StateBasedPushBoxEnvtask.
- class magbotsim.rl_envs.object_manipulation.pushing.state_based_push_box_env.StateBasedPushBoxEnvB3(mover_params: dict[str, Any] | None = None, initial_mover_zpos: float = 0.003, std_noise: ndarray | float = 1e-05, render_mode: str | None = 'human', render_every_cycle: bool = False, num_cycles: int = 40, collision_params: dict[str, Any] | None = None, object_ranges: MutableMapping[str, tuple[float, float]] = {'depth': (0.02, 0.02), 'height': (0.06, 0.06), 'mass': (0.3, 0.3), 'radius': (0.05, 0.05), 'segment_width': (0.02, 0.02), 'width': (0.06, 0.06)}, v_max_xy: float = 2, a_max_xy: float = 10, j_max_xy: float = 100, learn_mover_c_rotation: bool = False, p_max_c: float | None = None, v_max_c: float = 122.17305, a_max_c: float = 122.17305, j_max_c: float = 610.86524, object_sliding_friction: float = 0.6, object_torsional_friction: float = 0.0001, learn_jerk: bool = False, early_termination_steps: int | None = None, max_position_err: float = 0.05, collision_penalty: float = -10, per_step_penalty: float = -0.01, object_at_goal_reward: float = 1, use_mj_passive_viewer: bool = False)[source]
Bases:
StateBasedPushBoxEnvBenchmark 3 for the
StateBasedPushBoxEnvtask.
- class magbotsim.rl_envs.object_manipulation.pushing.state_based_push_box_env.StateBasedPushBoxEnvB4(mover_params: dict[str, Any] | None = None, initial_mover_zpos: float = 0.003, std_noise: ndarray | float = 1e-05, render_mode: str | None = 'human', render_every_cycle: bool = False, num_cycles: int = 40, collision_params: dict[str, Any] | None = None, object_ranges: MutableMapping[str, tuple[float, float]] = {'depth': (0.02, 0.02), 'height': (0.06, 0.06), 'mass': (0.3, 0.3), 'radius': (0.05, 0.05), 'segment_width': (0.02, 0.02), 'width': (0.06, 0.06)}, v_max_xy: float = 2, a_max_xy: float = 10, j_max_xy: float = 100, learn_mover_c_rotation: bool = False, p_max_c: float | None = None, v_max_c: float = 122.17305, a_max_c: float = 122.17305, j_max_c: float = 610.86524, object_sliding_friction: float = 0.6, object_torsional_friction: float = 0.0001, learn_jerk: bool = False, early_termination_steps: int | None = None, max_position_err: float = 0.05, collision_penalty: float = -10, per_step_penalty: float = -0.01, object_at_goal_reward: float = 1, use_mj_passive_viewer: bool = False)[source]
Bases:
StateBasedPushBoxEnvBenchmark 4 for the
StateBasedPushBoxEnvtask.
- class magbotsim.rl_envs.object_manipulation.pushing.state_based_push_box_env.StateBasedPushBoxEnvB5(mover_params: dict[str, Any] | None = None, initial_mover_zpos: float = 0.003, std_noise: ndarray | float = 1e-05, render_mode: str | None = 'human', render_every_cycle: bool = False, num_cycles: int = 40, collision_params: dict[str, Any] | None = None, object_ranges: MutableMapping[str, tuple[float, float]] = {'depth': (0.02, 0.02), 'height': (0.06, 0.06), 'mass': (0.3, 0.3), 'radius': (0.05, 0.05), 'segment_width': (0.02, 0.02), 'width': (0.06, 0.06)}, v_max_xy: float = 2, a_max_xy: float = 10, j_max_xy: float = 100, learn_mover_c_rotation: bool = False, p_max_c: float | None = None, v_max_c: float = 122.17305, a_max_c: float = 122.17305, j_max_c: float = 610.86524, object_sliding_friction: float = 0.6, object_torsional_friction: float = 0.0001, learn_jerk: bool = False, early_termination_steps: int | None = None, max_position_err: float = 0.05, collision_penalty: float = -10, per_step_penalty: float = -0.01, object_at_goal_reward: float = 1, use_mj_passive_viewer: bool = False)[source]
Bases:
StateBasedPushBoxEnvBenchmark 5 for the
StateBasedPushBoxEnvtask.
- class magbotsim.rl_envs.object_manipulation.pushing.state_based_push_box_env.StateBasedPushBoxEnvB6(mover_params: dict[str, Any] | None = None, initial_mover_zpos: float = 0.003, std_noise: ndarray | float = 1e-05, render_mode: str | None = 'human', render_every_cycle: bool = False, num_cycles: int = 40, collision_params: dict[str, Any] | None = None, object_ranges: MutableMapping[str, tuple[float, float]] = {'depth': (0.02, 0.02), 'height': (0.06, 0.06), 'mass': (0.3, 0.3), 'radius': (0.05, 0.05), 'segment_width': (0.02, 0.02), 'width': (0.06, 0.06)}, v_max_xy: float = 2, a_max_xy: float = 10, j_max_xy: float = 100, learn_mover_c_rotation: bool = False, p_max_c: float | None = None, v_max_c: float = 122.17305, a_max_c: float = 122.17305, j_max_c: float = 610.86524, object_sliding_friction: float = 0.6, object_torsional_friction: float = 0.0001, learn_jerk: bool = False, early_termination_steps: int | None = None, max_position_err: float = 0.05, collision_penalty: float = -10, per_step_penalty: float = -0.01, object_at_goal_reward: float = 1, use_mj_passive_viewer: bool = False)[source]
Bases:
StateBasedPushBoxEnvBenchmark 6 for the
StateBasedPushBoxEnvtask.
- class magbotsim.rl_envs.object_manipulation.pushing.state_based_push_box_env.StateBasedPushBoxEnvB7(mover_params: dict[str, Any] | None = None, initial_mover_zpos: float = 0.003, std_noise: ndarray | float = 1e-05, render_mode: str | None = 'human', render_every_cycle: bool = False, num_cycles: int = 40, collision_params: dict[str, Any] | None = None, object_ranges: MutableMapping[str, tuple[float, float]] = {'depth': (0.02, 0.02), 'height': (0.06, 0.06), 'mass': (0.3, 0.3), 'radius': (0.05, 0.05), 'segment_width': (0.02, 0.02), 'width': (0.06, 0.06)}, v_max_xy: float = 2, a_max_xy: float = 10, j_max_xy: float = 100, learn_mover_c_rotation: bool = False, p_max_c: float | None = None, v_max_c: float = 122.17305, a_max_c: float = 122.17305, j_max_c: float = 610.86524, object_sliding_friction: float = 0.6, object_torsional_friction: float = 0.0001, learn_jerk: bool = False, early_termination_steps: int | None = None, max_position_err: float = 0.05, collision_penalty: float = -10, per_step_penalty: float = -0.01, object_at_goal_reward: float = 1, use_mj_passive_viewer: bool = False)[source]
Bases:
StateBasedPushBoxEnvBenchmark 7 for the
StateBasedPushBoxEnvtask.
- class magbotsim.rl_envs.object_manipulation.pushing.state_based_push_box_env.StateBasedPushBoxEnvB8(mover_params: dict[str, Any] | None = None, initial_mover_zpos: float = 0.003, std_noise: ndarray | float = 1e-05, render_mode: str | None = 'human', render_every_cycle: bool = False, num_cycles: int = 40, collision_params: dict[str, Any] | None = None, object_ranges: MutableMapping[str, tuple[float, float]] = {'depth': (0.02, 0.02), 'height': (0.06, 0.06), 'mass': (0.3, 0.3), 'radius': (0.05, 0.05), 'segment_width': (0.02, 0.02), 'width': (0.06, 0.06)}, v_max_xy: float = 2, a_max_xy: float = 10, j_max_xy: float = 100, learn_mover_c_rotation: bool = False, p_max_c: float | None = None, v_max_c: float = 122.17305, a_max_c: float = 122.17305, j_max_c: float = 610.86524, object_sliding_friction: float = 0.6, object_torsional_friction: float = 0.0001, learn_jerk: bool = False, early_termination_steps: int | None = None, max_position_err: float = 0.05, collision_penalty: float = -10, per_step_penalty: float = -0.01, object_at_goal_reward: float = 1, use_mj_passive_viewer: bool = False)[source]
Bases:
StateBasedPushBoxEnvBenchmark 8 for the
StateBasedPushBoxEnvtask.
- class magbotsim.rl_envs.object_manipulation.pushing.state_based_push_box_env.StateBasedPushBoxEnvB9(mover_params: dict[str, Any] | None = None, initial_mover_zpos: float = 0.003, std_noise: ndarray | float = 1e-05, render_mode: str | None = 'human', render_every_cycle: bool = False, num_cycles: int = 40, collision_params: dict[str, Any] | None = None, object_ranges: MutableMapping[str, tuple[float, float]] = {'depth': (0.02, 0.02), 'height': (0.06, 0.06), 'mass': (0.3, 0.3), 'radius': (0.05, 0.05), 'segment_width': (0.02, 0.02), 'width': (0.06, 0.06)}, v_max_xy: float = 2, a_max_xy: float = 10, j_max_xy: float = 100, learn_mover_c_rotation: bool = False, p_max_c: float | None = None, v_max_c: float = 122.17305, a_max_c: float = 122.17305, j_max_c: float = 610.86524, object_sliding_friction: float = 0.6, object_torsional_friction: float = 0.0001, learn_jerk: bool = False, early_termination_steps: int | None = None, max_position_err: float = 0.05, collision_penalty: float = -10, per_step_penalty: float = -0.01, object_at_goal_reward: float = 1, use_mj_passive_viewer: bool = False)[source]
Bases:
StateBasedPushBoxEnvBenchmark 9 for the
StateBasedPushBoxEnvtask.